AI Inference - Faster, Cheaper, and More Secure
In this article, we'll examine what AI inference is, why traditional centralized AI inference approaches are not a good idea in the longterm, and how Gaia's decentralized platform can improve performance, cut costs, and enhance security for all your AI applications.

Imagine training for years for a marathon but never participating in one. Training AI models without deploying them for inference is similarly pointless — it’s the inference that delivers actual value of AI.
In this article, we'll examine what AI inference is, why traditional centralized AI inference approaches are not a good idea in the longterm, and how Gaia's decentralized platform can improve performance, cut costs, and enhance security for all your AI applications.
What Makes Inference Essential
Inference is the process where a trained AI model applies its learning to new data, generating predictions or making decisions.
Say you gave a picture of a dog (new data), and asked what animal it is, inference will process this data and make predictions, and will likely respond to you with an output, saying it’s a dog.

While training (where a really large set of data is provided to the AI model) creates the AI's capabilities, inference is where these capabilities translate into practical applications.
Here are some real-world examples:
- Voice assistants like Siri and Alexa process your speech in real-time, understanding commands and responding appropriately within milliseconds
- Autonomous vehicles make thousands of inference decisions every second, detecting objects, predicting movements, and adjusting controls to navigate safely
- Medical diagnostic systems analyze X-rays, MRIs, and CT scans to help radiologists identify potential abnormalities with greater accuracy
- Recommendation engines on streaming platforms and e-commerce sites continuously process user behavior to suggest relevant content and products
- Financial fraud detection systems evaluate transactions in real-time to identify suspicious patterns before approving purchases
In each case, the model's training is completed beforehand, it's the inference on the trained model that delivers the actual service or value to users.
Inference Optimization
AI model training generally happens once, you may have seen models like GPT-3, stating the dates until which it used the data for training. While training has massive computational requirements, inference presents an ongoing operational challenge:
Inference must run continuously (like ChatGPT), often serving millions of users simultaneously. It amounts to 90% of operational costs and a rapidly growing number of users.
AI service providers have found that optimizing inference performance can reduce the total cost of ownership by up to 70%, while simultaneously improving response times and user satisfaction.
How Inference Works
Inference simply converts a trained AI model into a practical application through four key stages:
- Model Loading: The trained AI neural network with its optimized weights and architecture is loaded into memory
- Data Preprocessing: Input data (like the photo of the dog) is normalized, tokenized, or otherwise prepared for the model
- Forward Pass Computation: Data flows through the neural network's layers (too technical to explain here)
- Post-processing: Conversion of raw output into presentable formats
AI inference workloads usually end up running on millions of servers worldwide to minimize latency for users. This distribution requirement is huge and creates unique challenges.
The Limitations of Centralized Inference Architecture
At the time of writing, most of the AI providers we have currently are centralized. But, traditional centralized AI inference faces several challenges that can impact performance, cost, and security.
- Architectural Bottlenecks: Several research supports the idea that centralized systems not only create a single point of failure, they experience performance degradation during peak loads.
- Network Latency Constraints: Centralized systems, network latency can significantly contribute to increase in inference response time.
- Scaling Economics: The GPU utilization in centralized AI clusters is often suboptimal, an inefficiency caused due to over-provisioning to counter bottlenecks.
- Data Privacy: Centralized AI architectures fundamentally compromise data privacy, forcing sensitive information to traverse networks and concentrate in vulnerable central repositories.
Gaia's Decentralized Inference Approach
Gaia operates a distributed AI infrastructure composed of individually and independently run "nodes" that collectively decentralize inferencing for AI applications. This represents a fundamental shift from centralized inference servers (like ChatGPT) to a distributed computing paradigm.
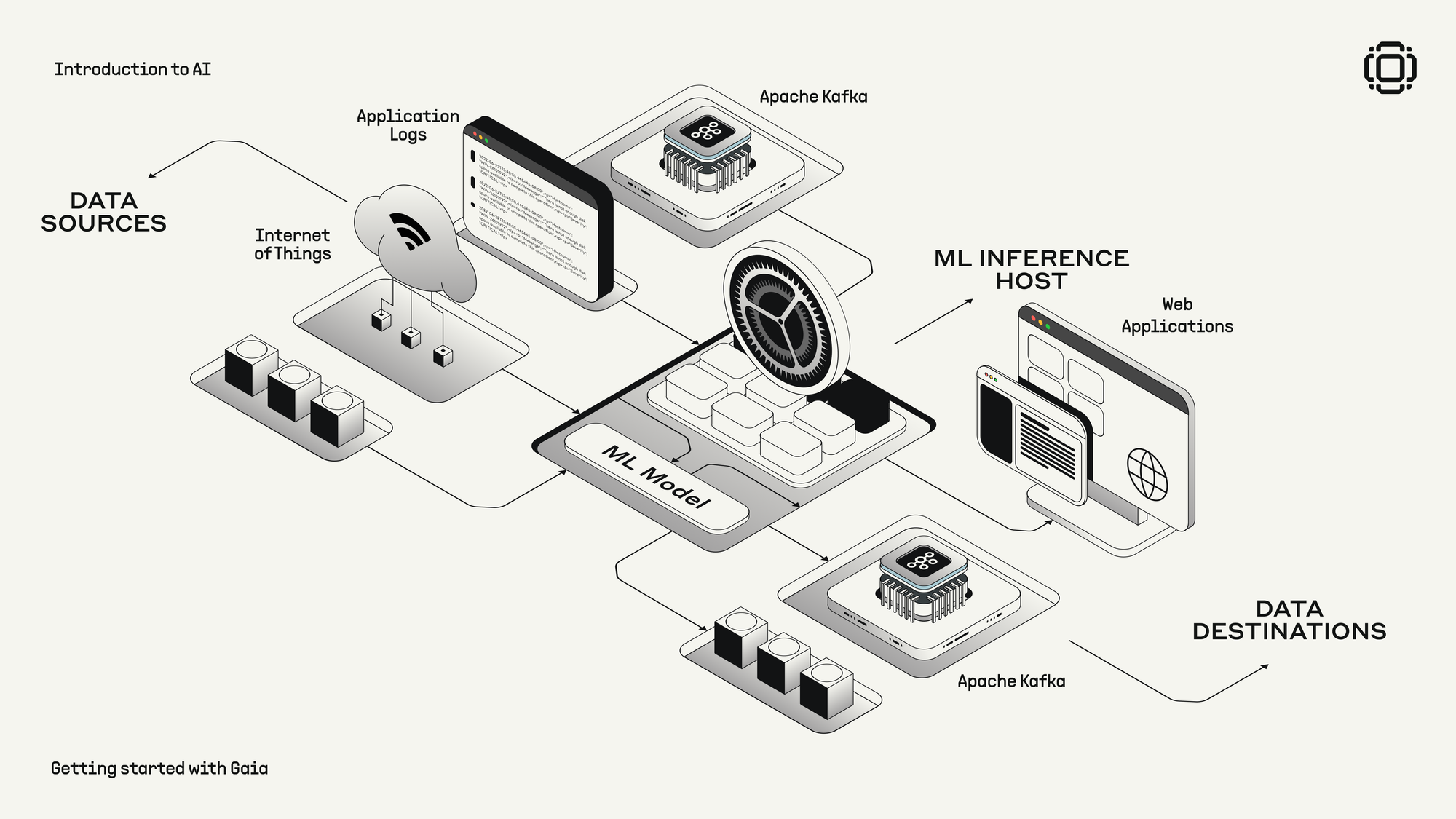
Gaia's platform:
- Distributes computational tasks across a network of independent nodes
- Creates a decentralized marketplace for AI agent services using Purpose Bound Money smart contracts
- Enables transparent operations where node activity can be audited and verified
- Focuses specifically on LLMs and AI agents, supporting their evolution from chatbots to autonomous agents
Technical Advantages of Decentralization
Decentralized architectural approach addresses several key limitations of centralized inference:
- Reduced Latency: By processing data closer to its source, decentralized inference minimizes the network transmission delays that account for the majority of inference response time.
- Improved Scalability: The ability to add nodes to the network enables horizontal scaling, avoiding the bottlenecks associated with vertical scaling in centralized systems.
- Enhanced Privacy: Decentralized inference allows sensitive data to be processed locally, minimizing the need for data transmission to remote servers—a critical consideration for regulated industries.
- Cost Optimization: Dynamic resource allocation through a marketplace model improves utilization efficiency and reduces the need for expensive over-provisioning.
The Future of Inference: Decentralized, Efficient, Secure
As AI deployment continues to accelerate, there is no doubt that the limitations of centralized inference will become increasingly apparent. Decentralized approaches represent the next evolution in AI infrastructure:
- Wider Accessibility: Availability of advanced models regardless of location or connectivity
- Improved Sustainability: Optimized resource utilization to reduce energy consumption
- Enhanced Privacy: Boxing sensitive data close to its source while extracting valuable insights
- Greater Efficiency: Reducing the operational costs of overall AI deployment
To explore further how decentralized inference might benefit you:
Decentralized inference represents an important evolution in how we deploy and run AI. Understanding its potential today positions you to make informed infrastructure decisions as AI continues to transform business and the world.
[PS: Subscribe to updates on AI inference optimization techniques and decentralized computing approaches.]